Text As Graph (TAG)
The Text As Graph (TAG) model conceptualizes of documents as a hypergraph for text. As you may be unfamiliar with a hypergraph model, we will briefly outline its key features. Like any graph, a hypergraph consists of nodes and edges, where the edges connect one node to another. A hypergraph contains both regular edges, which connect one node to one other node, and hyperedges, which connect a set of nodes to another set of nodes.
You can find more information about modeling text as a hypergraph in “It’s more than just overlap: Text As Graph”. For now, keep in mind that the hypergraph is a powerful data structure that allows you to represent a greater quantity of textual information in an inclusive and more refined way.
Why are we looking at TAG?
The only document model in wide use in digital editions projects is XML, which is the only technology that has sufficient maturity and a sufficiently large community to be practical for general production purposes. The reason we nonetheless introduce TAG (and LMNL) is that looking at non-XML ways of modeling documents encourages us to think first about the model, and then about the relationship of the model to the syntax. In other words, thinking about how to model documents in LMNL and TAG can improve the quality of our models, whether we use XML or an alternative.
A study of TAG’s features, therefore, serve the purpose of encouraging critical thinking about document modeling. The TAG model is under active development, so in the following paragraphs we will not discuss its syntax, query language or schema, but we focus on the properties of the data model.
TAG edges
The TAG data model distinguishes a number of different edges; below we describe just the two main ones.
TAG undirected edges
All edges in TAG’s hypergraph are undirected. The graph models you may be more familiar with, such as a variant graph, have directed edges. This means the edges can only be traversed from node A to node B. Undirected edges, conversely, can be traversed in both ways.
TAG hyperedges
TAG uses hyperedges to associate markup with its textual content. Hyperedges can connect one or more nodes with each other, in contrast to regular edges that connect one node to another node. This means that there can be multiple Markup nodes on one Text node. An example of a hyperedge is given below.
TAG Nodes
The TAG model distinguishes four kinds of nodes in the hypergraph. They are briefly described below and illustrated using a simple example.
TAG Document node
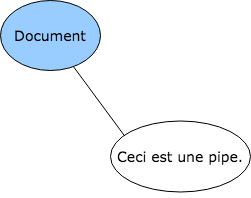
The Document node represents a single TAG document. It marks the start of a sequence of Text nodes and serves as a root node. See the root node in the image below.
TAG Text nodes
A Text node represents (a part of) the textual content of the document. Whitespace is included in the textal content. The simplest TAG document, which contains only text and no markup, looks something like:
TAG Markup nodes
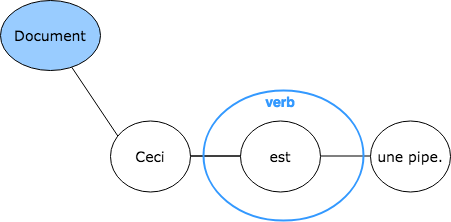
Markup nodes store the name of the markup. They are connected to one or more Text nodes with an hyperedge. In the figure below, the hyperedge connects the Markup node verb with the Text node containing est.
TAG Annotation nodes
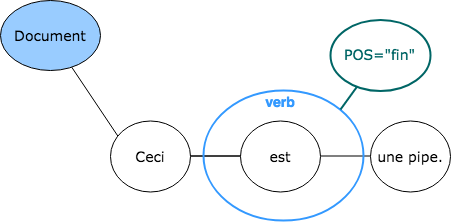
Annotations in TAG are comparible to XML attributes. Information is stored as a key:value pair. Annotation nodes have two properties: the name of the annotation (the key) and the value of the annotation (the value).
Below an illustration of an annotation with the key POS and the value fin on the Markup node:
Modeling text in TAG
We mentioned above that the properties of the hypergraph for text data model cater for the modeling of complex text features. In other words: what’s hard in XML is not hard in TAG.
Let’s take a look at the textual examples we used when illustrating the limitations of XML and see how they translate to TAG.
Overlap
Consider a fragment of Percy Bysshe Shelley’s “Ozymandias” (1818):
Who said—“Two vast and trunkless legs of stone
Stand in the desart …
What in a XML transcription leads to overlapping structures and thus not well formed XML:
<line><phrase>Who said —</phrase> <phrase>“Two vast and trunkless legs of stone</line>
<line>Stand in the desart….</phrase></line>
is easily expressed in TAG:
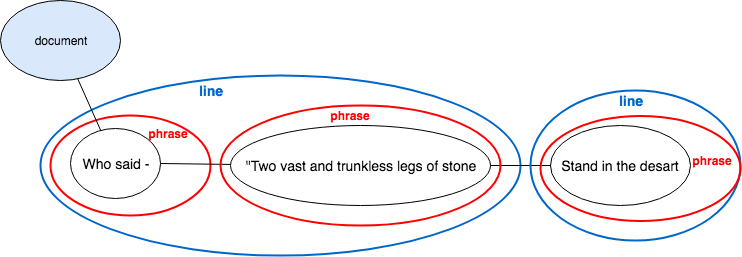
The phrase “Two vast and trunkless legs of stone stand in the desart” is split between two lines, each of which also contains other phrases. There is no valid way to mark this up in XML except by prioritizing one hierarchy (phrases or lines) and representing the other with empty milestones. In TAG, however, neither hierarchy is primary; phrases and lines both contain Text nodes, and both types of relationships are encoded in the same way. (See also a complete graphic representation of “Ozymandias”, generated by Alexandria.)
{kind=link}
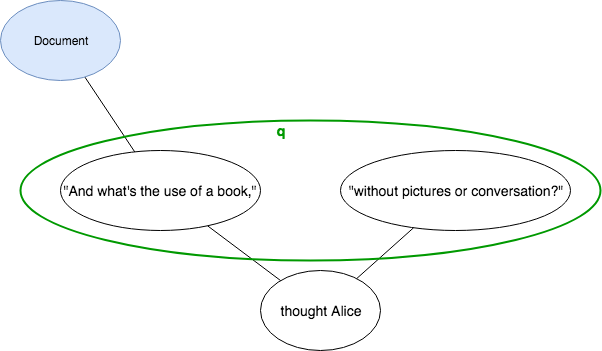
Discontinuity
<q>"and what is the use of a book,"</q> thought Alice <q>"without pictures or conversation?"</q>
can be modeled in TAG:
TAG syntax
TAGML stands for TAG Markup Language and, as syntax, it is a serialization of the TAG model. It is designed to represent in a straightforward manner all features of a text.
A simple TAGML example is:
[line>The rain in Spain falls mainly on the plain.<line]
with the [line> being the start-tag and the <line] being the end-tag. For every start-tag there should be an end-tag, and vice versa.
Curious about TAG?
As noted above, up-to-date information about TAG is maintained at the TAG portal on GitHub. Also take a look at the Balisage 2018 paper for more details on TAGML and its relation to existing markup languages.